
An extremely short developer's guide to OpenAI (and the basics of generative AI)

The AI Service Provider
An AI service provides intelligent capabilities that developers can integrate into their applications.
The depth and breadth of these capabilities depend on two things: 1) the quality of the models the service uses, and 2) how well developers can tap into those models (via an API).
Using OpenAI (https://platform.openai.com/docs/) as an example, let’s examine each of the three components: models, capabilities, and the API, and learn the fundamentals of generative AI in the process.
Models
Generative AI has grown out of deep learning (with the help of a few milestone inventions, namely, Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Transformer Models), where vast neural networks are trained on large datasets to produce models that are used to accomplish intelligent tasks. What a model can perform is determined by the type of data used to train it and how much fine-tuning went into it.
Models and Training
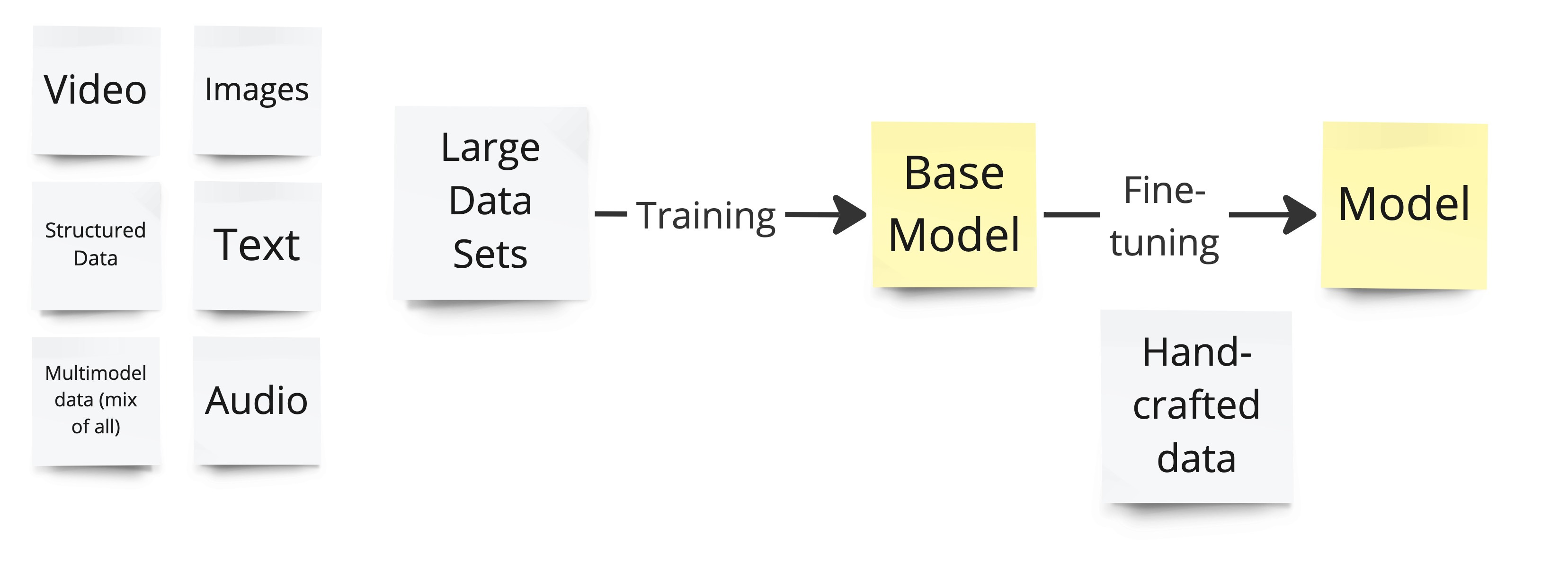
Models trained on images, for example, produce images, models trained on images + text, produce images based on text and so on.
The first thing to do when examining an AI service is, therefore, to look at the models they offer.
OpenAI's models are listed here: https://platform.openai.com/docs/models/overview
They include:
GPTs for generating natural language
DALL-E for generating images
Whisper for converting audio into text
and many more.
But what is a model, actually? A model is nothing other than a set of parameters (that represent the weights of the neural network that came out of the training). When you install, for example, an open-source large-language-model like Llama-2 on your computer, you will find a 100s GB large file on your drive that captures exactly those parameters (plus another file that handles the user interaction - see a video by Karpathy1 for an excellent introduction).
One more thing to know about models is that they are trained during (at least) two phases:
the base training uses a massive amount of data (e.g. large chunks of the internet) to produce a general model that is not yet that useful for the end user
followed by a fine-tuning phase that turns the base model into something better, like a question-and-answering assistant (e.g. ChatGPT)
Fine-tuning doesn’t stop here.
A model can further be fine-tuned by the user. Either through more training or directly on the prompt by including the sample data in the chat (so-called "few-shot prompting"2)
Capabilities
Let's look at OpenAI's capabilities. A few we have already mentioned.
Model capabilities

Text generation: The key function of large language models is to generate text based on text input provided by the user (also called "prompts"). LLMs have been trained to understand language and behave in a question-and-answer manner.
Image generation: Takes text or images to produce new images.
Vision: Takes an image and allows to ask questions about it.
Text-to-speech and Speech-to-text: Can be used to transcribe voice or produce audio based on text.
Moderation: Takes text as input and flags the content for potential policy violations. Can be used to filter user input.
Function-calling: Allows to connect a model with external tools provided by the user.
Embeddings: An embedding is a numerical representation of text, allowing efficient handling of text search and other use cases.
Fine-tuning: Creates a new model based on custom training data and default instructions. Useful for repetitive tasks that require additional training, complex prompts or rules. After fine-tuning, the customisation is integrated into the new model.
Some capabilities provide immediate value (e.g., text generation), while others are only useful in combination with other tools (e.g., function calling).
The remaining question now is to figure out how to access those capabilities. OpenAI offers two APIs: endpoints and assistants.
API
Endpoints
Here are again the capabilities, but this time we include the endpoints.
Endpoints and capabilities
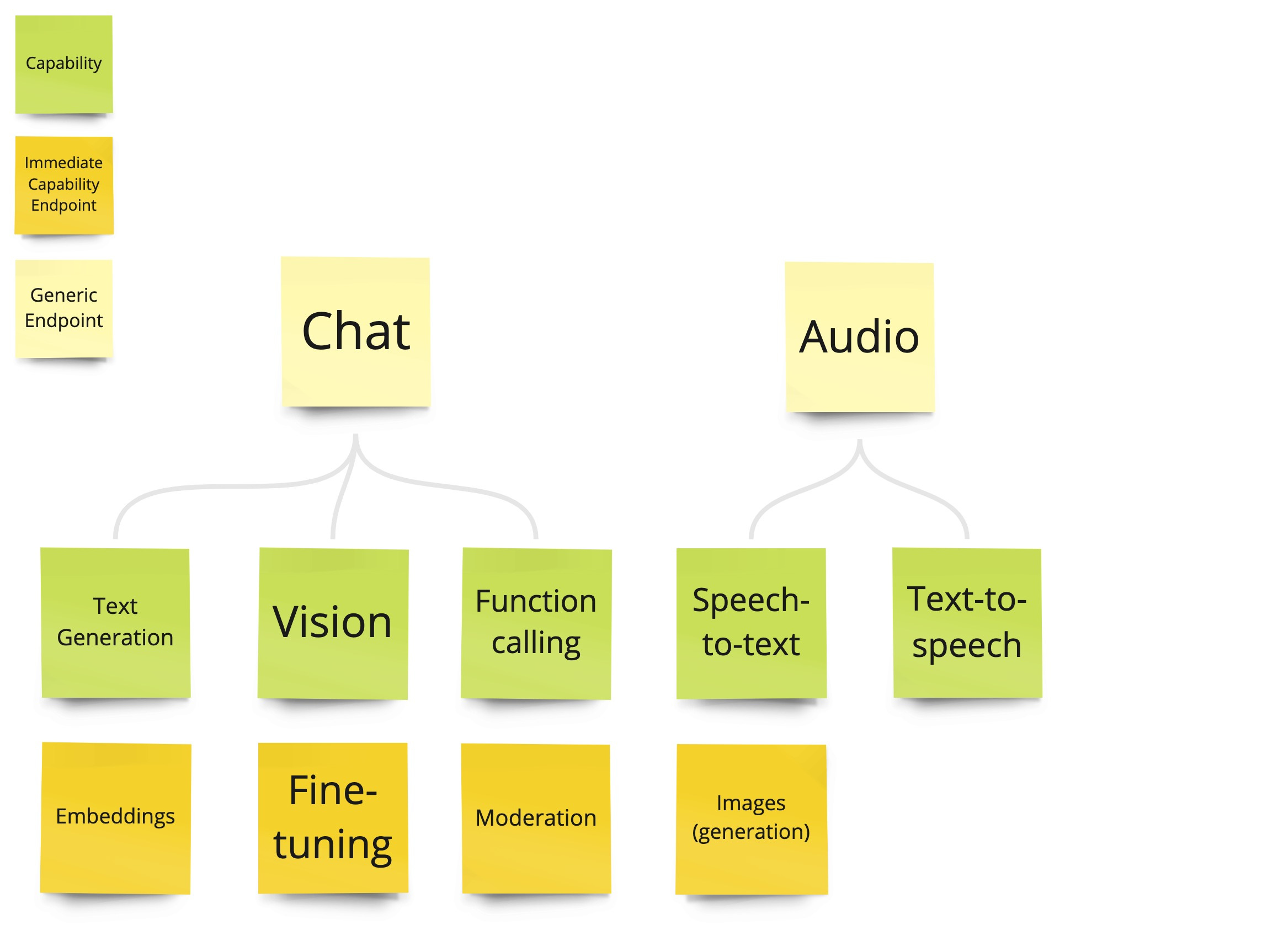
As we can see, some capabilities can be accessed directly from an endpoint, while others are only available indirectly through a generic endpoint (Chat and Audio).
Chat is the most capable endpoint, resembling a chat with ChatGPT. Previously called "chat completion," it works by sending a question to the endpoint and, depending on the question asked, returning more or less complex answers. It combines text completion, image recognition and function calling. Audio is the access point to create speech from text and vice versa. The remaining capabilities have their own endpoint.
Assistants API
The endpoints we have mentioned so far directly tap into a capability. The Assistants API offers a more sophisticated experience.
Assistants API
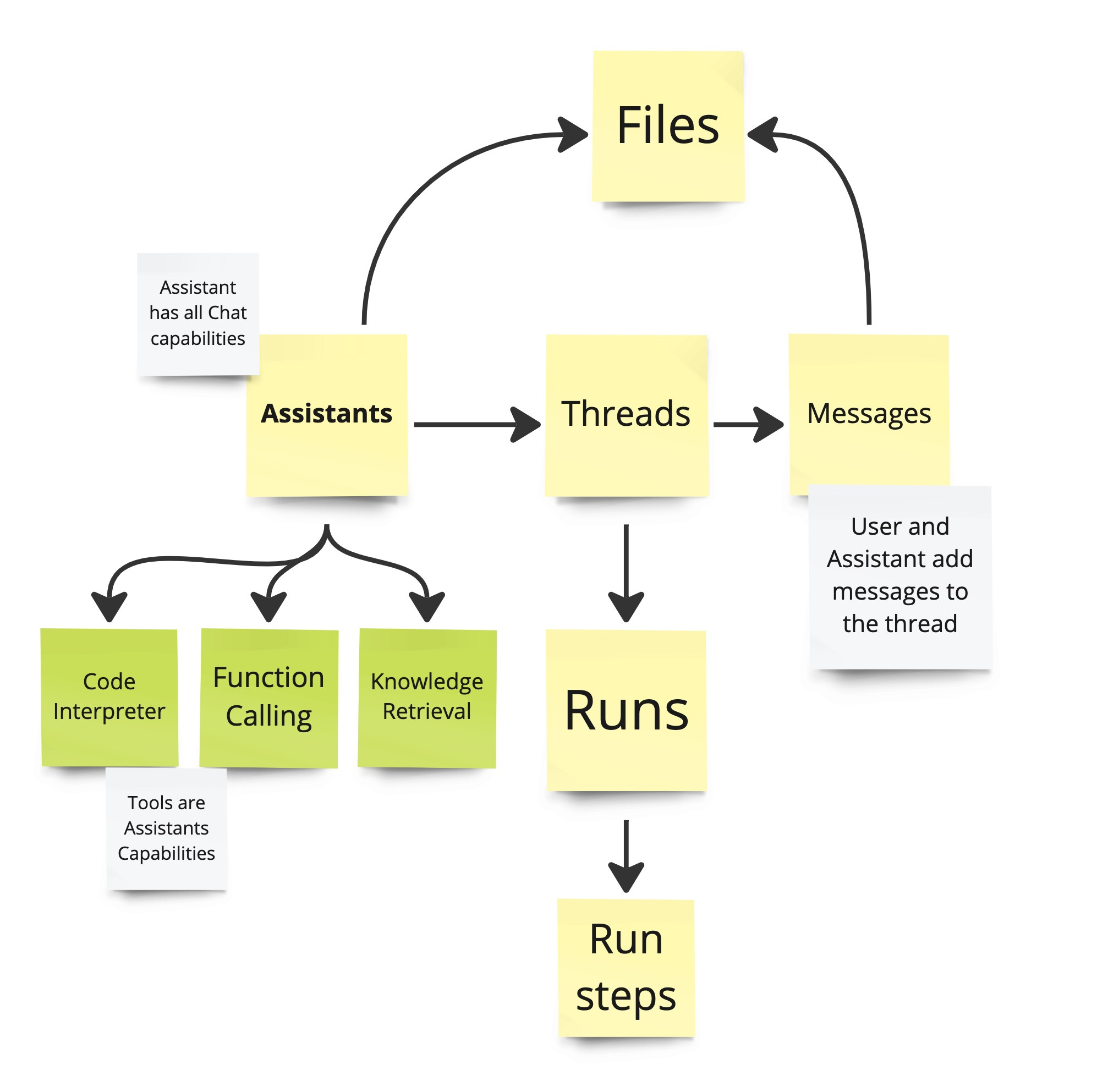
You can think of it as the Chat endpoint but with more features. Mainly, conversations with an assistant are captured with Threads and Runs, making it possible to have several ongoing chat sessions. Also, assistants make it possible to provide files to the AI (to ask questions about them, or for "Knowledge Retrieval", see below).
Assistants have access to so-called "Tools," which are additional capabilities, only available through the Assistants API (except for function-calling, which is possible with the Chat endpoint). Code Interpreter "allows the Assistants API to write and run Python code in a sandboxed execution environment". Knowledge Retrieval gives the Assistant access to your own documents. It works by uploading a File to Open AI, which then automatically chunks, indexes and stores the embeddings so that the assistant can search and retrieve the document's content.
Tokens, Embeddings, Prompt Engineering
There are a few more things left worth mentioning:
Tokens: models process text in chunks called tokens3. The details don't matter much when using an LLM, except that the cost of using a service is based on the amount of tokens that have been used.
Embeddings: we have already mentioned that they are a numerical representation of text in the form of a vector, which makes it possible to compare the similarity between documents by comparing the vectors mathematically.
Prompt Engineering: working with LLMs is vastly different from how humans have interacted with computers so far. In the past, a computer required *exact* instructions, that would produce the same outcome with every execution. A slight mistake in the input could produce a useless result. LLMs are often capable of handling faulty or incomplete input (e.g. spelling mistakes), but they can make mistakes no matter how well the input was conceived. Also, the ability of LLMs to be "creative" leads to producing a different answer every time you ask the same question. This new approach to human-machine interaction is called "prompt engineering," and it is very worthwhile to invest time studying to make the best out of the new tools.
Thanks for reading. Please reach out for comments, questions, or suggestions.